华为云MapReduce服务 功能优势解析与上云无忧的数据处理实践
在当今数据驱动的时代,企业面临着海量数据处理的严峻挑战。传统的数据处理架构往往在扩展性、成本和运维复杂度上捉襟见肘。华为云MapReduce服务(MRS)应运而生,作为一款全托管的企业级大数据处理平台,它旨在为企业提供一站式、高性能、安全可靠的大数据解决方案,真正实现“上云无忧,数据处理服务”。
一、服务简介:企业级大数据处理的云上基石
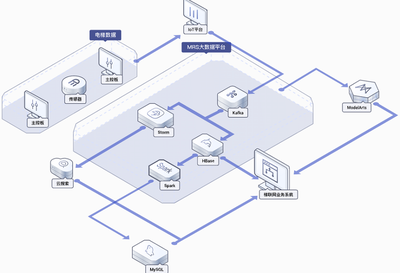
华为云MapReduce服务是一个基于开源生态(如Apache Hadoop、Spark、Flink、HBase、Kafka等)构建的云原生大数据集群。它并非简单地将开源组件搬运上云,而是深度融合了华为云的基础设施优势与多年的大数据技术积淀,提供了开箱即用、弹性伸缩、运维简化的全托管服务。用户无需关心底层基础设施的部署、监控、扩容与升级,可以专注于业务逻辑与数据分析本身,极大降低了大数据平台的技术门槛和运维成本。
其核心在于提供了一个统一的计算引擎和存储框架,能够对PB级甚至EB级别的数据进行批处理、交互式查询、实时流处理以及机器学习等多种计算。通过MRS,企业可以快速构建数据仓库、用户画像、实时推荐、日志分析、风险控制等多种大数据应用。
二、核心功能优势:为何选择华为云MRS?
- 全托管与极致弹性:MRS提供完全托管服务,从集群创建、组件配置、监控告警到版本升级,全部由华为云自动化完成。其弹性伸缩能力尤为突出,可根据业务负载(如CPU/内存使用率、作业队列长度)自动增加或减少计算节点,实现资源的按需使用和成本优化,从容应对业务高峰与低谷。
- 高性能与开源兼容:服务底层基于华为云高性能计算(ECS)、存储(OBS)和网络,并对开源组件进行了深度优化,在相同资源配置下能获得更优的计算性能。它100%兼容开源接口,确保现有的Hadoop/Spark生态工具、作业和代码可以平滑迁移上云,保护企业已有投资,实现无缝过渡。
- 企业级安全与可靠性:安全是企业上云的生命线。MRS提供多维度的安全保障:
- 网络安全:支持VPC隔离、安全组、细粒度的IP白名单控制。
- 数据安全:支持数据传输与静态加密(集成KMS)、细粒度的权限访问控制(Ranger/Kerberos)。
- 容灾与高可用:核心组件均采用高可用部署,数据支持多副本存储,并结合华为云跨可用区(AZ)部署能力,提供金融级的数据可靠性与业务连续性保障。
- 运维智能化与成本透明:提供可视化的集群监控大盘,关键指标一目了然。内置智能运维助手,可对集群健康状态进行诊断,提供优化建议。成本管理清晰透明,用户可详细查看资源消耗情况,结合弹性伸缩有效控制总体拥有成本(TCO)。
- 丰富的组件与生态集成:一站式集成Hadoop、Spark、Flink、Hive、HBase、Kafka、Presto等数十种主流大数据组件,并支持与华为云数据仓库DWS、数据湖探索DLI、AI平台ModelArts等服务的无缝对接,轻松构建从数据接入、处理、存储到分析与智能化的完整数据流水线。
三、典型场景案例:上云无忧的数据处理实践
场景一:离线数据仓库与批量分析
某大型零售企业需要每日分析前一天的全国销售数据、库存情况和用户行为,生成各类报表供管理层决策。传统自建Hadoop集群资源利用率低,扩容周期长。迁移至华为云MRS后,利用其Hive/Spark组件构建云上数据仓库。每日凌晨,通过定时作业自动从业务数据库同步数据至MRS HDFS,执行复杂的ETL和聚合分析任务。借助弹性伸缩功能,在数小时的作业执行期间自动扩容计算资源,任务完成后自动缩容,分析效率提升50%,整体成本下降约30%。
场景二:实时流处理与风险监控
一家金融机构需要实时处理每秒数万笔的交易流水,进行反欺诈和异常交易监测。他们使用MRS提供的全托管Flink服务,构建实时流处理管道。交易数据通过Kafka实时接入,Flink作业进行实时规则计算、特征提取和模型推理(集成ModelArts),毫秒级内识别风险交易并告警。MRS保障了Flink作业的高可用与Exactly-Once语义,运维团队无需深入Flink底层,即可保障7x24小时的关键业务稳定运行。
场景三:交互式查询与数据探索
互联网公司的产品运营团队需要即时查询海量用户日志,进行灵活的数据探查和问题定位。基于MRS部署的Presto或Impala服务,他们可以直接对存储在OBS(对象存储)或HDFS中的原始或预处理数据执行亚秒级到秒级的交互式SQL查询,快速获得洞察,而无需等待漫长的ETL和报表生成流程。存储与计算分离的架构,使得数据可被多个计算引擎共享,资源利用更高效。
###
华为云MapReduce服务通过将复杂的大数据平台管理任务转化为简单的云服务,赋予了企业敏捷、经济、安全的数据处理能力。无论是从零开始构建大数据平台,还是将现有本地Hadoop集群迁移上云,MRS都提供了平滑的路径和强大的支撑。其“上云无忧”的核心承诺,正助力越来越多的企业摆脱基础设施束缚,释放数据潜能,专注于业务创新与价值创造。在数字化转型的浪潮中,华为云MRS无疑是企业构建数据竞争力的可靠云上基石。
如若转载,请注明出处:http://www.co-toker.com/product/25.html
更新时间:2026-06-18 13:54:05