鹅厂分享 从初创到成熟,一款App需要分析哪些核心数据及如何构建数据处理服务

在移动互联网竞争激烈的今天,数据驱动决策已成为产品成功的基石。无论是初创团队验证想法,还是成熟产品优化增长,一套清晰的数据分析体系与强大的数据处理服务都至关重要。本文将以腾讯(鹅厂)的实践经验为参照,梳理一款App在不同发展阶段需要关注的核心数据指标,并探讨如何构建与之匹配的数据处理服务体系。
一、不同发展阶段的核心数据分析重点
1. 初创期 (0-1,验证与留存)
此阶段的目标是验证产品核心价值,找到早期种子用户并让他们留下来。数据分析应聚焦于最基础的指标,避免过度复杂。
- 核心价值指标: 功能使用深度、核心路径转化率。例如,对于一个社交App,是“成功发布动态/完成一次聊天”的比例;对于一个工具App,是“核心功能任务完成率”。
- 用户获取与质量: 渠道来源分析、用户画像(基础属性)。关注哪个渠道来的用户留存更高、更活跃。
- 留存与活跃: 次日/7日/30日留存率 是生命线。需要分析新用户的初始行为与长期留存的关系。日活跃用户(DAU)、周活跃用户(WAU)的绝对数及趋势。
- 问题发现: 崩溃率、关键操作错误率、用户反馈(评论、工单)的文本分析。
2. 成长期 (1-100,增长与规模化)
产品价值得到验证后,重点转向快速增长和规模化获取用户。数据分析需更精细化,支持增长实验。
- 增长漏斗分析: 从市场曝光→下载→激活→注册→首次关键行为→持续活跃的全链路转化分析。定位流失环节。
- 用户分群与行为分析: 对用户进行更精细的分群(如新老用户、渠道、版本、行为特征群组),对比不同群组的留存、活跃和付费情况。分析用户行为序列和生命周期。
- A/B测试与实验数据: 任何产品功能、UI/UX、运营策略的改动,都应通过A/B测试评估其对核心指标(如留存、转化)的影响。
- 营收与商业化数据(如果适用): 付费用户数(APA)、付费率、平均每用户收入(ARPU)、平均每付费用户收入(ARPPU)、生命周期价值(LTV)。
3. 成熟期 (规模化运营,效率与生态)
用户规模趋于稳定,重点转向提升运营效率、深化用户价值、构建生态和防御竞争。
- 生态系统健康度: 用户互动网络指标(如社交App的好友密度、互动频率)、内容生态指标(如内容生产与消费比、优质内容占比)。
- 深度参与与流失预警: 用户参与度分层(如高价值用户、沉默用户、流失风险用户)。构建流失预警模型,提前干预。
- 运营效率与ROI: 各渠道、各运营活动的投入产出比(ROI)精细化核算。用户分层的精准营销效果分析。
- 市场份额与行业对标: 通过第三方数据或市场调研,监控自身产品的市场份额、用户心智份额,并与竞品对标。
- 长期趋势与归因: 分析DAU/MAU(粘性比率)、营收等核心指标的长期趋势,并进行多维度的归因分析(如功能迭代、市场活动、季节性因素)。
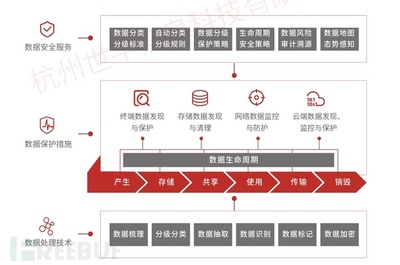
二、支撑数据分析的数据处理服务架构
无论处于哪个阶段,稳定、高效、灵活的数据处理服务是获得可靠洞察的前提。一个典型的数据处理服务栈(参考业界及鹅厂实践)包含以下层次:
1. 数据采集与埋点
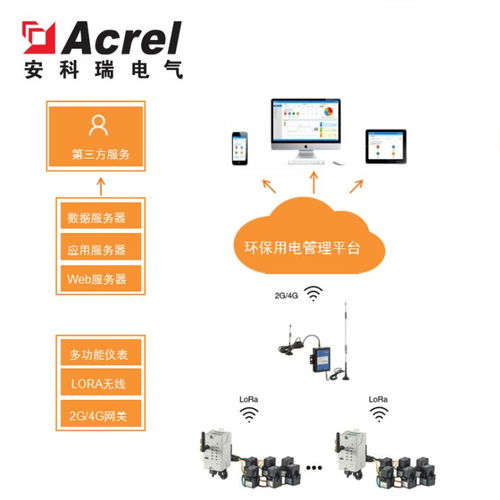
工具与规范: 建立统一的埋点规范与管理平台(如腾讯的MTA、神策、GrowingIO等类似工具),确保数据口径一致。涵盖全端(iOS、Android、Web、小程序等)自动化采集与手动埋点。
关键: 事件设计(Event)、用户标识(UID)、上下文属性(Properties)的清晰定义。在初创期就应打好基础,避免后期重建数据。
2. 数据接入与传输
* 服务: 使用高可用的数据收集网关(如基于Nginx/OpenResty自研或使用Flume、Logstash),通过SDK将数据实时或批量传输到数据中心。保障数据不丢失、低延迟。
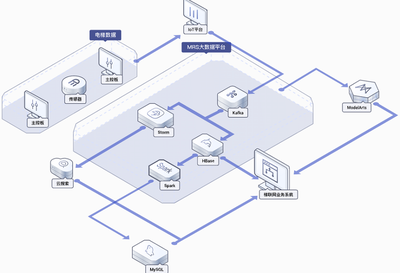
3. 数据存储与计算
实时数据流: 使用Kafka、Pulsar等消息队列承接实时数据流,供实时监控和实时计算(如Flink、Spark Streaming)使用,用于实时大盘、反作弊、即时推送等场景。
批处理与数据仓库: 原始日志存入HDFS或对象存储(如COS/OSS)。通过ETL(Extract-Transform-Load)流程,使用Hive、Spark、Flink等计算引擎进行清洗、关联、聚合,并分层(ODS原始层、DWD明细层、DWS汇总层、ADS应用层)存入数据仓库(如Hive、ClickHouse、腾讯TDW等),形成主题明确、易于查询的数据模型。
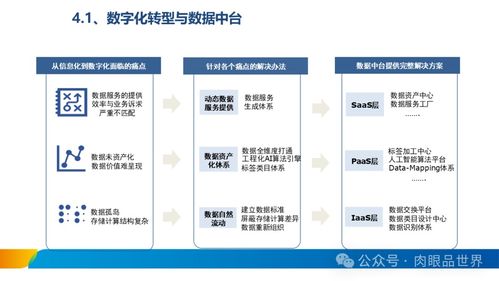
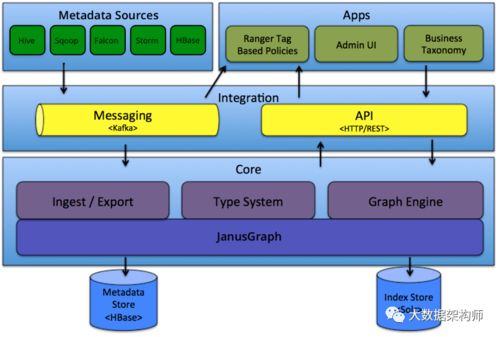
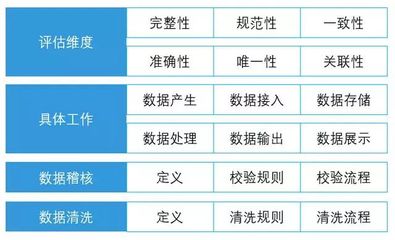
4. 数据管理与治理
元数据管理: 记录数据表的来源、含义、血缘关系(从采集到报表的完整链路),方便团队协作和数据发现。
数据质量监控: 对数据完整性、准确性、及时性设置监控告警(如每日数据量波动、关键字段空值率)。
* 权限与安全: 严格的数据访问权限控制,遵守GDPR等数据隐私法规,对敏感数据脱敏。
5. 数据应用与服务
分析平台: 提供灵活的可视化报表(如自助BI工具Tableau、帆软、腾讯云图)、OLAP查询引擎(如Presto、Kylin、ClickHouse)和用户行为分析平台(如神策、GrowingIO的深度替代或自研),供产品、运营、分析师自主探索数据。
数据服务化(Data API): 将清洗后的关键数据(如用户标签、实时指标)通过API或数据总线的方式,提供给推荐系统、广告系统、风控系统、客服系统等业务系统实时调用。
* 算法模型平台: 为流失预测、用户分层、个性化推荐等高级分析提供数据特征和模型训练/部署支持。
###
从初创到成熟,App数据分析的焦点从 “验证价值、关注留存” 转向 “驱动增长、优化漏斗” ,最终达到 “提升效率、经营生态” 。而底层的数据处理服务,则需要从一开始就具备 可扩展、规范化和高可用 的架构视野,从埋点规范做起,逐步构建起从采集、传输、存储、计算到应用的全链路能力。
鹅厂的经验表明,数据建设并非一蹴而就,它需要与产品发展同步规划、持续迭代。初期可以借助成熟的第三方服务快速启动,但在规模扩大后,拥有自主可控、深度定制化的数据中台和能力,往往是构筑长期竞争优势的关键。记住:你无法优化你无法衡量的东西。 尽早并持续地关注正确的数据,并投资于可靠的数据基础设施,将为你的App成功铺平道路。
如若转载,请注明出处:http://www.co-toker.com/product/16.html
更新时间:2026-06-18 22:39:56