微服务架构下数据报告服务的快速构建 从数据处理到服务化的高效路径
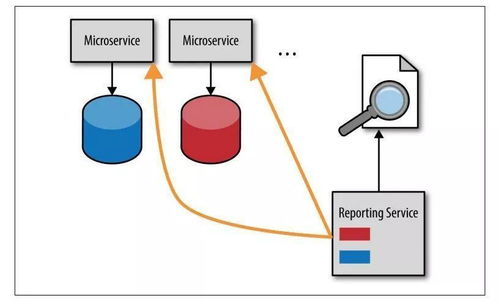
在当今数据驱动的时代,快速、灵活地构建数据报告服务是企业数字化转型的关键需求。微服务架构以其松耦合、独立部署和可扩展的特性,为构建此类服务提供了理想的框架。本文将系统性地阐述如何在微服务环境中,高效构建一个从数据处理到报告生成的服务。
一、 核心架构设计:解耦数据处理与报告呈现
微服务架构的核心在于“单一职责”和“高内聚、低耦合”。因此,构建数据报告服务的第一步是将其拆分为两个独立但又协同工作的核心微服务:
- 数据处理服务:负责数据的抽取、清洗、转换、聚合与计算(即ETL/ELT过程)。它是整个系统的“发动机”,专注于业务逻辑和算法,不关心数据如何展示。
- 报告服务:负责接收处理后的数据,根据预设模板或动态配置,生成可视化图表、表格或PDF/Excel报告,并通过API或前端界面对外提供。
这种分离使得数据处理逻辑的迭代优化不会影响报告生成的界面和用户体验,反之亦然。
二、 快速构建数据处理服务
- 技术选型:选择轻量级、高性能且易于容器化的框架。例如,使用 Python (FastAPI/Flask) + Pandas/Numpy 进行快速原型开发和数据处理;或使用 Java (Spring Boot) + Apache Spark 处理超大规模数据集。对于流处理,可考虑 Apache Flink 或 Kafka Streams。
- 数据接入与标准化:
- 通过 REST API、消息队列(如Kafka, RabbitMQ) 或 数据库CDC(变更数据捕获)工具(如Debezium) 接入源数据。
- 定义清晰的 数据契约(Data Contract) 或使用 Avro/Protobuf 序列化,确保服务间数据格式的一致性。
- 核心处理逻辑容器化:将数据处理代码封装到 Docker 容器中。这保证了环境的一致性,并便于在Kubernetes等编排平台上进行弹性伸缩。
- 结果存储:处理后的中间或最终结果应存储在高性能、适合查询的数据库中,如:
- 时序数据库(如InfluxDB, TimescaleDB):适用于时间序列报告。
- 列式存储(如Apache Druid, ClickHouse):适用于快速聚合查询和大规模数据分析。
- 缓存(如Redis):存储热数据,加速报告生成。
- 服务化暴露:为处理服务提供管理API,用于触发处理任务、监控任务状态、更新处理规则等。
三、 快速构建报告服务
- 报告模板与引擎:
- 动态报告:采用前后端分离模式。前端(如Vue.js, React)使用 ECharts, D3.js, AntV 等图表库进行可视化,通过API从报告服务获取JSON格式的已处理数据。
- 静态/格式化报告:使用模板引擎(如Jinja2 for Python, Thymeleaf for Java)或专业报表工具(如JasperReports, BIRT)生成PDF/Word/Excel。报告服务负责填充数据到模板并渲染输出。
- 数据获取:报告服务通过内部REST调用或直接从结果存储库(如ClickHouse)查询,获取数据处理服务产出的、已结构化的数据。避免在报告服务中执行复杂的原始数据计算。
- API设计与聚合:设计清晰的报告查询API,支持参数化(如时间范围、维度筛选)。对于需要组合多个数据源的复杂报告,报告服务可以扮演一个 API聚合网关 的角色,并行调用多个下游数据处理服务,整合结果后返回。
- 缓存与性能:对生成的报告结果或常用查询结果进行缓存(HTTP缓存或Redis),显著提升重复访问的响应速度。
四、 关键支撑与协同
- 服务发现与通信:利用 Consul, Eureka 或 Kubernetes Service 实现服务发现。服务间通过 REST(同步)或 异步消息(如Kafka,适用于耗时处理)进行通信。
- 配置中心:将数据处理规则、报告模板、数据库连接等配置外置到 Apollo, Nacos 或 Spring Cloud Config 中,实现动态更新,无需重启服务。
- 任务调度:对于定时报告或周期数据处理,使用 分布式任务调度框架,如 Apache Airflow、DolphinScheduler 或 XXL-JOB,以DAG(有向无环图)形式编排数据处理任务的依赖与执行。
- 监控与日志:集成 Prometheus 收集指标(如请求延迟、错误率、数据处理耗时),使用 Grafana 制作监控看板。通过 ELK(Elasticsearch, Logstash, Kibana)或 Loki 栈集中管理日志,便于问题排查。
五、 快速构建实践路径
第一步:最小可行产品(MVP)
选定一个核心报告需求,构建一个简单的数据处理任务(如每日销售汇总)和一个展示该数据的API或简单页面。使用最直接的技术栈快速上线验证。
第二步:服务拆分与标准化
将MVP中的代码明确拆分为数据处理和报告生成两个独立项目(微服务)。定义两者之间的API接口和数据格式。将服务容器化。
第三步:引入关键中间件
逐步引入消息队列解耦、配置中心管理配置、任务调度器管理定时任务,提升服务的健壮性和可维护性。
第四步:完善与扩展
根据需求,增加新的数据处理管道和报告模板。优化性能,引入缓存,完善监控告警体系。
###
在微服务架构下快速构建数据报告服务,精髓在于“分而治之”和“标准化”。通过将复杂的数据流水线拆解为职责单一、可独立部署的服务,并借助成熟的云原生中间件进行集成与管理,团队能够以敏捷的方式迭代开发,灵活响应业务变化,最终交付一个高性能、可扩展且易于维护的数据报告平台。
如若转载,请注明出处:http://www.co-toker.com/product/14.html
更新时间:2026-06-18 16:20:52